
An Efficient Approach for Security and Privacy Preserving based on Machine Learning and Federated Learning (FL): Analysis and Performance Optimization for Secure Multiparty Computing
DOI:
https://doi.org/10.62019/5t3k4c10Keywords:
Machine Learning, Collaborative Learning, Zero Knowledge Proofs, Blockchain Technology, Decentralized Learning, Federated Averaging.Abstract
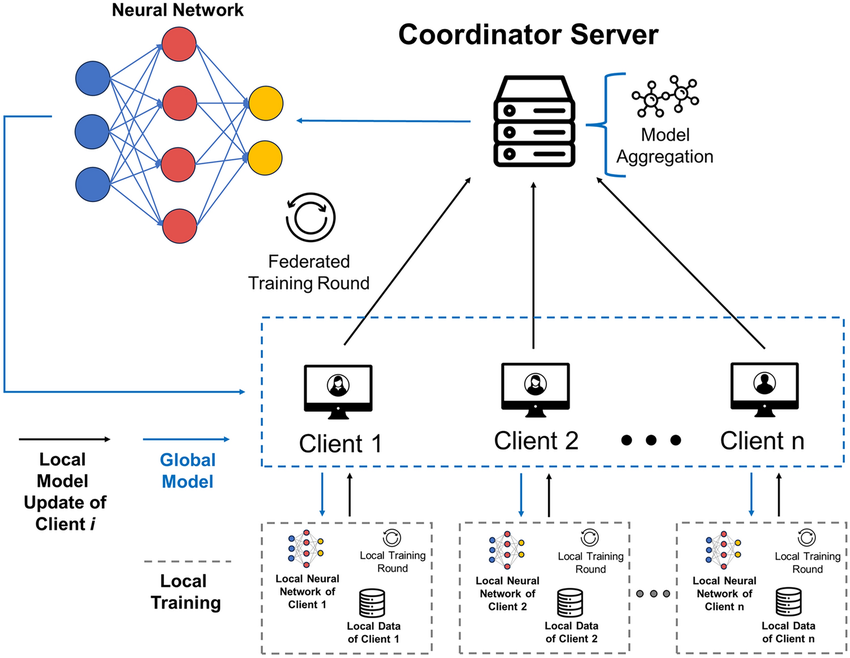
Federated Learning (FL) is an approach that allows numerous users to train a single machine learning model with the oversight of a central server, and with their training data stored locally on their devices. The approach is relevant in alleviating the risks associated with violations in data privacy. It is a process by which a pool of clients collaborates towards solving machine learning problems, with a central coordinator being the one who coordinates the entire process. The paper will review the latest advances in privacy-preserving federated learning and discuss it in the context of machine learning. It assesses privacy-related solutions, which are already in existence, such as secure aggregation, meta-learning, blockchain technology, decentralized training, searchable encryption, and data privacy mechanisms and zero-knowledge proofs. Federated learning (FL) is an emerging technology that can be used in the realm of the intelligence of the Internet of Things. However, the information that is model-related can be shared in FL and reveal the sensitive data of the participants. In this regard, we propose a new privacy-preserving FL framework, which is founded on a new chained secure multiparty computing technique, which we call chain-PPFL. The scheme we are proposing is based mostly on two mechanisms: 1) a single-masking mechanism, which protects the information that is exchanged between participants in a serial chain frame and 2) a chained-communication mechanism, which allows the masked information to be communicated between participants in a serial chain frame. We run large-scale experiments with respect to simulation by comparing the training accuracy and the leak defence to other state-of-the-art schemes with two publicly available data sets (MNIST and CIFAR-100). We established data sample distributions (IID and NonIID), and training models (CNN, MLP and L-BFGS) in our experiments. The experiment results show that the chain-PPFL scheme can offer a realistic privacy preservation (which is the same as the various privacy with ϵ to near zero) to FL at the cost of communication, and without compromising the accuracy and convergence rate of the training model.
Downloads
Published
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
How to Cite




