
Low-Resource Balochi Named Entity Recognition: Corpus Construction and Multilingual Transformer Evaluation
DOI:
https://doi.org/10.62019/en6geh21Abstract
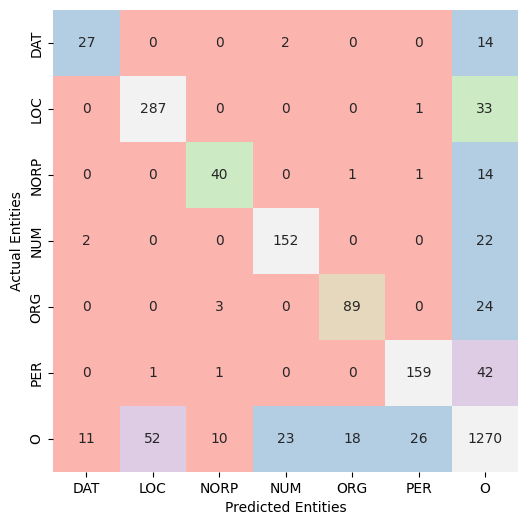
Named Entity Recognition (NER) remains largely unexplored for Balochi, a morphologically complex, low-resource language spoken by approximately 8 to 10 million population across Pakistan, Iran, and Afghanistan. This paper makes three contributions to address this gap. First, we introduce a IOB2-annotated Balochi NER corpus, comprising 1,909 sentences, 48,920 tokens, and 4,359 named entity annotations across six semantic categories: Location (LOC), Person (PER), Nationality/Religion/Political Group (NORP), Number (NUM), Organization (ORG), and Date/Time (DAT). Second, we benchmark four multilingual pre-trained Transformer models , mBERT, XLM-R, mmBERT, and RemBERT, under identical fine-tuning conditions using the AdamW optimizer with cosine learning rate scheduling. Third, we provide a comprehensive evaluation encompassing entity-level F1-scores, confusion matrix analysis, and learning curve examination. RemBERT achieved the best overall performance with a micro-averaged F1-score of 0.85, outperforming XLM-R (F1 = 0.84), mmBERT (F1 = 0.83), and mBERT (F1 = 0.81). The entities like NORP and DAT were the most challenging categories across all models due to class imbalance and high lexical ambiguity, while mmBERT exhibited the most pronounced overfitting behaviour. These results establish the first quantitative NER baseline for Balochi and demonstrate that multilingual pre-trained models, particularly RemBERT, can be effectively adapted to extremely low-resource languages with limited annotated data.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Nazish Basir , Rafique Ahmed Vighio, Beenish Ansari, Noorulain patoli , Danish Nazir Arain, Aijaz Ali

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
How to Cite




